Redis是一个key-value存储系统,数据存储在内存中,通常被称为数据结构服务器
优点
性能极高,速度很快
- 纯内存操作,是已知性能最快的key-value数据库:
读的速度是110000次/s,写的速度是81000次/sHashMap 的查找和操作的时间复杂度均为O(1)
- 纯内存操作,是已知性能最快的key-value数据库:
单线程操作,避免了频繁的上下文切换
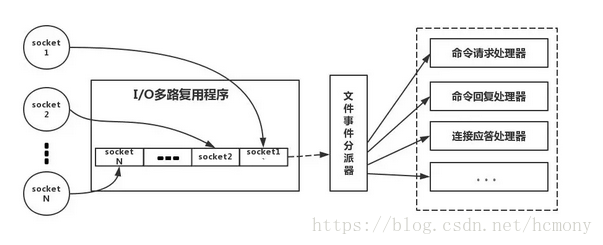
采用了非阻塞I/O多路复用机制:我们的redis-client在操作的时候,会产生具有不同事件类型的socket。在服务端,有一段I/0多路复用程序,将其置入队列之中。然后,文件事件分派器,依次去队列中取,转发到不同的事件处理器中。
丰富的数据类型
5种 - Strings(字符串)、List(列表)、 Hash(哈希)、Set(集合)、Sorted Set(有序集合)
丰富的特性
- 订阅发布 Pub / Sub 功能
- Key 过期策略
- 事务
- 原子性(事务中的命令要么全部被执行,要么全部都不执行)
- 一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断
- 支持多个 DB
- 计数
持久化存储
- 可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用
缺点
- 由于是内存数据库,所以,单台机器存储的数据量,跟机器本身的内存大小。虽然redis本身有key过期策略,但是还是需要提前预估和节约内存。如果内存增长过快,需要定期删除数据
- 修改配置文件,进行重启,将硬盘中的数据加载进内存,时间比较久。在这个过程中,redis不能提供服务
- redis是单线程的,单台服务器无法充分利用多核服务器的CPU
- 缓存穿透、雪崩、击穿问题
数据类型
Strings(字符串)
最基本的数据类型,value可以包含任何数据,比如jpg图片
1 | 127.0.0.1:6379> set foo bar |
List(列表)
可以在头部(左边)或尾部(右边)添加新元素,利用lrange命令,做基于redis的分页功能,性能极佳,用户体验好
1 | LPUSH citylist Beijing Shanghai |
Hash(哈希)
键值对集合,一个string类型的field和value的映射表,特别适合用于存储对象,比如存cookieId
1 | 127.0.0.1:6379> HMSET cityhash Beijing Guangzhou |
Set(集合)
堆放的是一堆不重复值的集合,通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)
1 | 127.0.0.1:6379> SADD cityset Beijing Guangzhou |
Sorted Set(有序集合)
与集合一样,存放不重复值的集合。但是每个元素都会关联一个double类型的分数,集合中的元素能够按score进行排列。可以做排行榜应用
1 | 127.0.0.1:6379> ZADD cityzset 0 Beijing |
过期策略与内存淘汰机制
Redis采用的是定期删除+惰性删除策略。不采用定时删除的原因是:虽然Key到了过期时间及时释放,但是十分消耗CPU资源,在大并发请求中,CPU不能集中时间做要紧的事情,还要花时间删除Key。并且定时器的创建会影响性能。
定期删除是Redis默认每100ms检查,是否有过期的Key,过期则删除。注意不是将所有的Key都检查,而是随机抽取进行检查。如果只采用这种策略,将导致很多过期的Key过期没有被删除。
惰性删除是获取到Key的时候,检查一下,如果过期就删除返回null。
当然,两种策略还是不能保证所有到期的Key被删除,当Redis的内存不足以容纳新写入数据时,走内存淘汰机制
1 | // 在redis.conf中有一行配置 |
- noeviction:新写入操作会报错(不推荐)
- allkeys-lru:移除最近最少使用的Key(推荐,最常用)
- allkeys-random:随机移除某个Key(不推荐)
- volatile-lru:在设置了过期时间Key中,移除最近最少使用的Key(不推荐)
- volatile-random:在设置了过期时间Key中,随机移除某个Key(不推荐)
- volatile-ttl:在设置了过期时间Key中,有更早过期的Key优先移除(不推荐)
ps:如果没有设置 expire 的key, 不满足先决条件(prerequisites); 那么 volatile-lru, volatile-random 和 volatile-ttl 策略的行为, 和 noeviction(不删除) 基本上一致。
内存淘汰策略用于处理内存不足时的需要申请额外空间的数据;过期策略用于处理过期的缓存数据。
缓存穿透、雪崩、击穿问题
缓存穿透
用户不断请求缓存和数据库中都没有的数据,导致数据库压力过大
解决方案:
利用互斥锁:缓存失效的时候,先去获得锁,得到锁,再去请求数据库。没得到锁,则休眠一段时间重试
提供一个能迅速判断请求是否有效的拦截机制,比如:利用布隆过滤器,内部维护一系列合法有效的key,迅速判断,请求所携带的key是否合法。如果不合法,直接返回
如果查询返回的数据为空(不管数据是否存在,或系统故障),仍把这个空结果进行缓存,设置很短的过期时间
缓存击穿
并发请求 缓存中没有或过期但数据库中有的数据,导致数据库压力过大
解决方案:
- 设置热点数据永不过期
- 加互斥锁(以下是伪代码)
- 从缓存取数据
- 如果结果没有为null,去获取锁,获取成功,去数据库获取数据
- 把数据库中获取的数据存到缓存,释放锁
- 如果获取锁失败,暂停100ms再重新去获取数据
缓存雪崩
缓存同一时间大面积的失效,这个时候又来了一波请求,导致数据库压力过大甚至down机。和缓存击穿不同,缓存击穿指并发查同一条数据,雪崩是很多数据
解决方案:
- 过期时间设置随机,防止同一时间大面积失效现象发生
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同的缓存数据库中
- 设置热点数据永不过期
- 利用互斥锁
数据库双写一致性
本来想看懂redis与数据库双写一致性问题,太复杂了,太绕了,没试过,整蒙圈了,又是先删缓存再更新数据库,又是先更新数据库再删缓存,完了这两种都有弊端,没有确切的答案。挣扎了一番,我决定以后再看!先po文章链接:链接