题目描述:在未排序的数组中找到第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
示例 1:
输入: [3,2,1,5,6,4] 和 k = 2
输出: 5示例 2:
输入: [3,2,3,1,2,4,5,5,6] 和 k = 4
输出: 4说明:
你可以假设 k 总是有效的,且 1 ≤ k ≤ 数组的长度。
方法一:暴力
1 | class Solution { |
复杂度分析:
- 时间复杂度:O(NlogN),这里 N 是数组的长度,算法的性能消耗主要在排序,JDK 默认使用快速排序,因此时间复杂度为 O(NlogN)。
- 空间复杂度:O(1),这里是原地排序,没有借助额外的辅助空间。
执行结果:通过
- 执行用时:2 ms, 在所有 Java 提交中击败了91.30%的用户
- 内存消耗:38.5 MB, 在所有 Java 提交中击败了87.53%的用户
方法二:基于快速排序的选择方法
思想
- 通过 paritition 减治
- partition(切分)操作总能排定一个元素,还能够知道这个元素它最终所在的位置,这样每经过一次 partition(切分)操作就能缩小搜索的范围
- 切分过程可以不借助额外的数组空间,仅通过交换数组元素实现
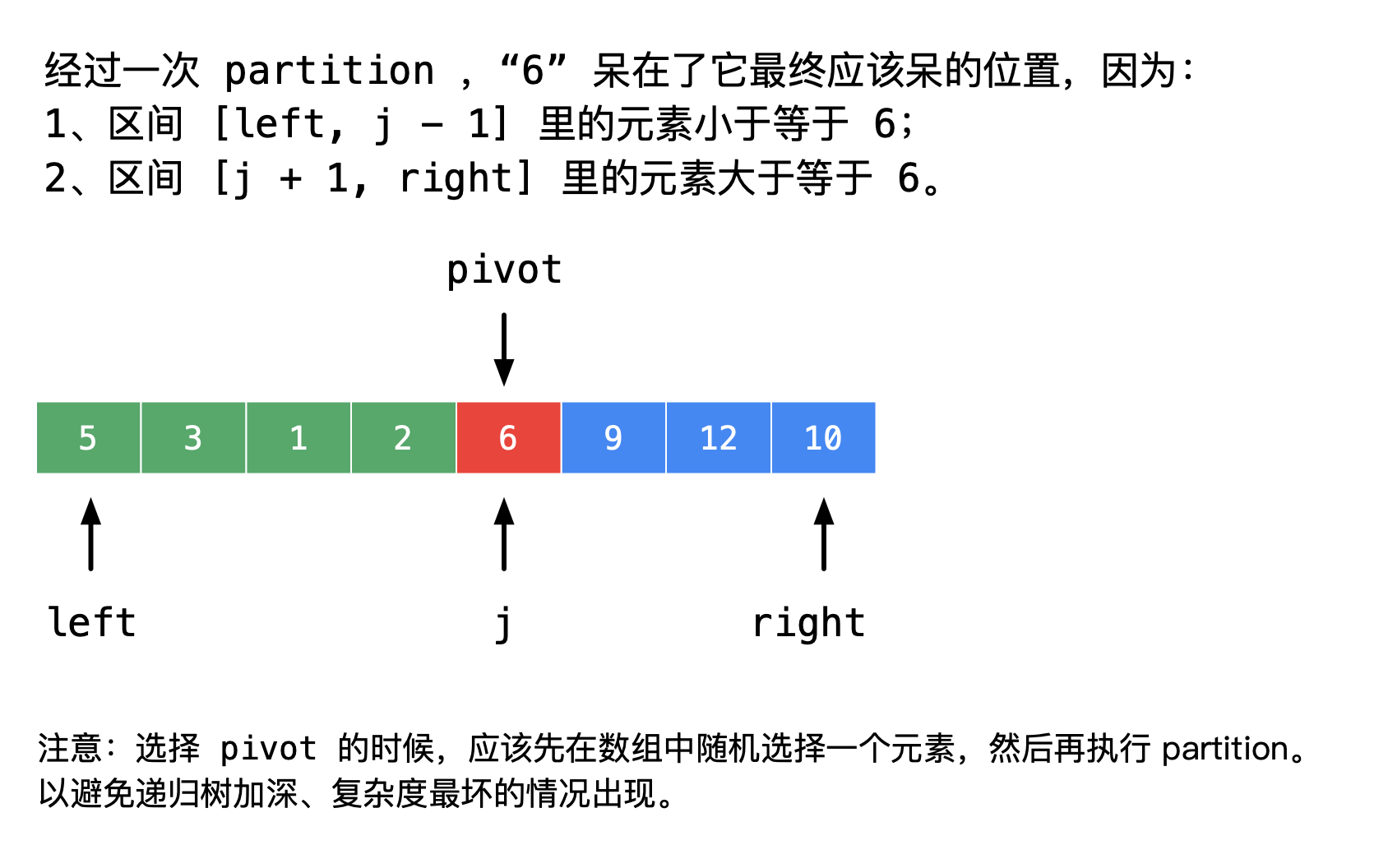
paritition 切分操作
- 对于某个索引 j,nums[j] 已经排定,即 nums[j] 经过 partition(切分)操作以后会放置在它 “最终应该放置的地方”;
- nums[left] 到 nums[j - 1] 中的所有元素都不大于 nums[j];
- nums[j + 1] 到 nums[right] 中的所有元素都不小于 nums[j]。
代码
为了应对极端测试用例,使得递归树加深,可以在循环一开始的时候,随机交换第 1 个元素与它后面的任意 1 个元素的位置;
说明:最极端的是顺序数组与倒序数组,此时递归树画出来是链表,时间复杂度是 O(N^2),根本达不到减治的效果。
1 | import java.util.Random; |
复杂度分析:
时间复杂度:O(N),这里 N 是数组的长度。用主定理分析:
复杂度:T(n) = T(n/2) + n
首先不是一个完全的递归树,按照每次排序刚好定位到中间来想,递归树的下一层只有T(n/2),不考虑另一半;
其次,每一层递归树都要遍历对应的, “分而治之”的”分“后的数组长度,所以+n 这样来算
用Master method,T(n) = aT(n/b) + f(n), f(n) = n,a=1,b=2, f(n) = Ω(n的 (以b为底a的对数 + x) 次方 ),x>0, 所以T(n) = O(f(n))=O(n)
第一次交换,算法复杂度为O(N)。这里在确定基准值的相对位置(在K的左边或者右边)之后不用再对剩下的一半进行处理。也就是说第二次插入的算法复杂度不再是O(N)而是O(N/2),接下来的过程是1+1/2+1/4+…….. < 2,换句话说就是一共是O(2N)的算法复杂度也就是O(N)的算法复杂度。
空间复杂度:O(1),原地排序,没有借助额外的辅助空间。
执行结果:通过
执行用时:1 ms, 在所有 Java 提交中击败了99.09%的用户
内存消耗:38.3 MB, 在所有 Java 提交中击败了97.33%的用户
方法三:基于堆排序的选择方法
排序思想
建立一个大根堆,做 k - 1次删除操作后堆顶元素就是我们要找的答案。堆排序过程中,不全部下沉,下沉
nums.length-k+1,然后堆顶可以拿到我们top k答案了
将待排序序列构造成一个大顶堆
- 注意:这里使用的是数组,而不是一颗二叉树
此时:整个序列的 最大值就是堆顶的根节点
将其 与末尾元素进行交换,此时末尾就是最大值
然后将剩余 n-1 个元素重新构造成一个堆,这样 就会得到 n 个元素的次小值。如此反复,便能的得到一个有序序列。
堆排序步骤图解
对数组 4,6,8,5,9 进行堆排序,将数组升序排序。
步骤一:构造初始堆
- 给定无序序列结构 如下:注意这里的操作用数组,树结构只是参考理解
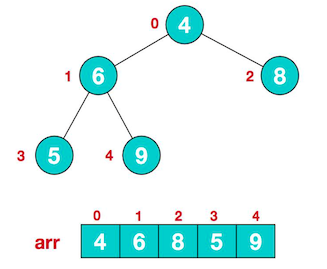
将给定无序序列构造成一个大顶堆。
- 此时从最后一个非叶子节点开始调整,从左到右,从上到下进行调整。
叶节点不用调整,第一个非叶子节点 arr.length/2-1 = 5/2-1 = 1 ,也就是 元素为 6 的节点。
比较时:先让 5 与 9 比较,得到最大的那个,再和 6 比较,发现 9 大于 6,则调整他们的位置。
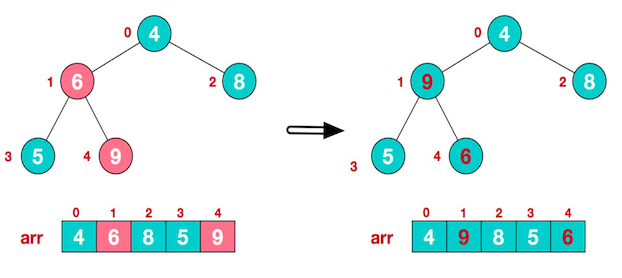
- 找到第二个非叶子节点 4,由于 [4,9,8] 中,9 元素最大,则 4 和 9 进行交换
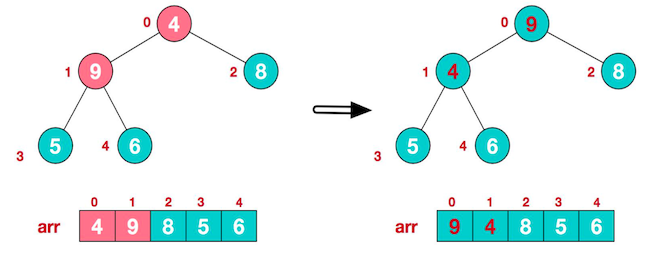
- 此时,交换导致了子根 [4,5,6] 结构混乱,将其继续调整。[4,5,6] 中 6 最大,将 4 与 6 进行调整。
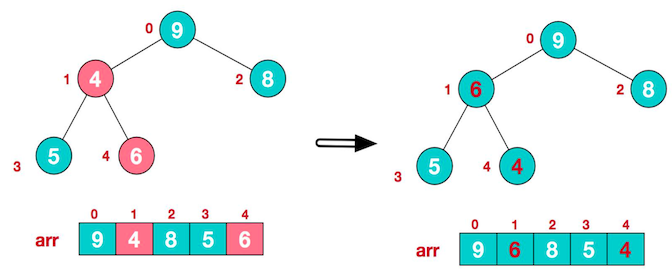
此时,就将一个无序序列构造成了一个大顶堆。
步骤二:将堆顶元素与末尾元素进行交换
将堆顶元素与末尾元素进行交换,使其末尾元素最大。然后继续调整,再将堆顶元素与末尾元素交换,得到第二大元素。如此反复进行交换、重建、交换。
将堆顶元素 9 和末尾元素 4 进行交换
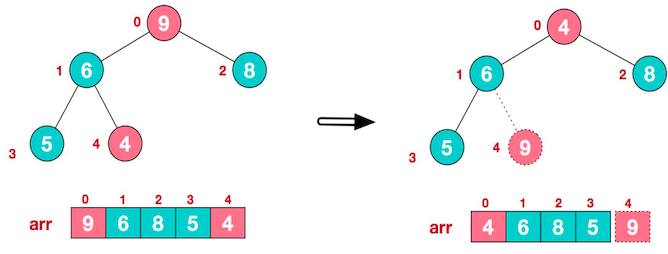
重新调整结构,使其继续满足堆定义
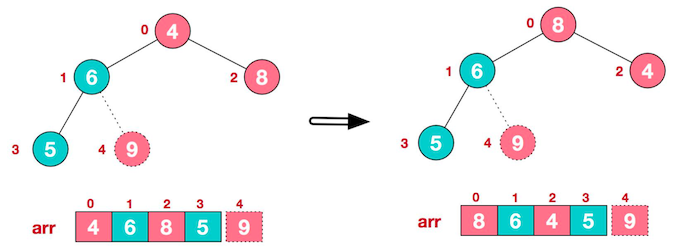
再将堆顶元素 8 与末尾元素 5 进行交换,得到第二大元素 8
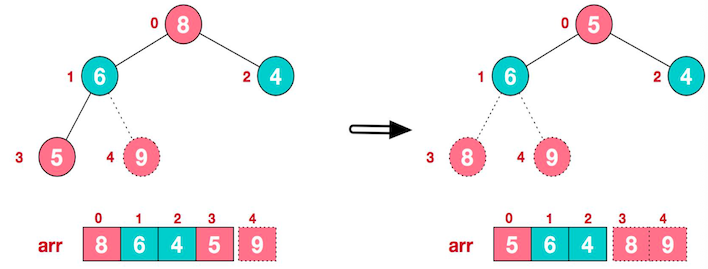
后续过程,继续进行调整、交换,如此反复进行,最终使得整个序列有序
总结思路
- 将无序序列构建成一个堆,根据升序降序需求选择大顶堆
- 将堆顶元素与末尾元素交换,将最大元素「沉」到数组末端
- 重新调整结构,使其满足堆定义,然后继续交换堆顶与当前末尾元素,反复执行调整、交换步骤,直到整个序列有序。
注意事项
- 第一步构建初始堆
- 是自底向上构建,从最后一个非叶子节点开始。
- 第二步下沉操作
- 让尾部元素与堆顶元素交换,最大值被放在数组末尾,并且缩小数组的length,不参与后面大顶堆的调整
- 第三步调整
- 是从上到下,从左到右,因为堆顶元素下沉到末尾了,要重新调整这颗大顶堆
代码
可以参考作为堆排序的模板
1 | class Solution { |
进行堆排序
1 | findKthLargest(nums,nums.length) |
复杂度分析
- 时间复杂度:O(nlogn),建堆的时间代价是 O(n),删除的总代价是 O(klogn),因为 k<n,故渐进时间复杂为 O(n+klogn)=O(nlogn)。
- 空间复杂度:O(1)。只需要常数的空间存放若干变量。
执行结果:通过
执行用时:2 ms, 在所有 Java 提交中击败了89.59%的用户
内存消耗:38.6 MB, 在所有 Java 提交中击败了76.42%的用户